引言:什么是RFS——RobotFramework+Selenium2library,本系列主要介绍web自动化验收测试方面。
( @齐涛-道长 新浪微博)
又是好久木有来写了。。这次我们将分层进行到底。
首先我们看一下testflow这个resource里的内容。

可以看到在这个搜索测试的关键字中,我们堆积了很多最底层的代码,这样是不够灵活的。
对于我们分层来说,还是要把一些底层的代码级关键字继续拆分出来。
先做2个,后面的类似。这时候我们看res1的资源下面有一个打开浏览器的,这是我之前添加了,目的就是留到这里来分层的。
我们把open browser这一行挪过去。

记得给res1加载Selenium2Library
然后在res1下面新增一个输入搜索内容,并把第二行input text挪过来。

剩下的第3行、第45行、第6行,也分别增加3个关键字。效果如图:
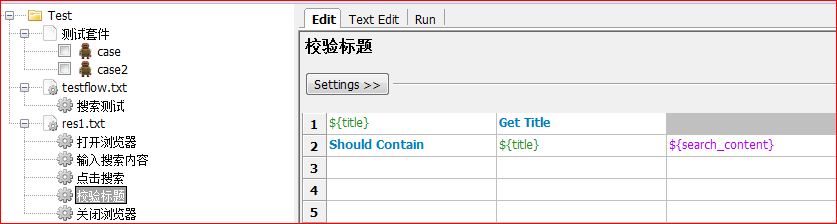
接着我们把对应的搜索测试中的代码都换成相应的关键字。

这样还不行,因为有一些关键字是有参数的,我们最好把他们继续完善相应的参数。
打开浏览器:
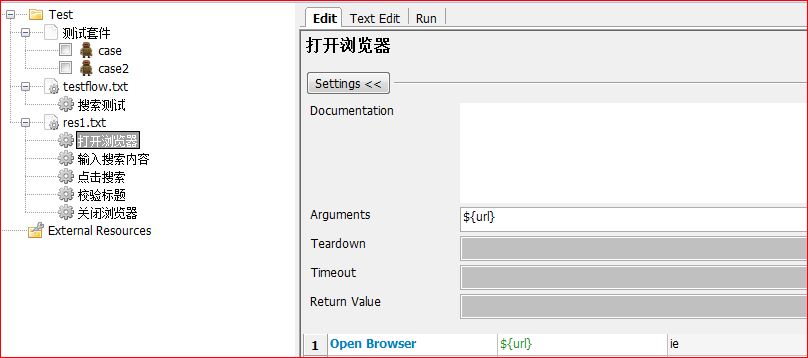
输入搜索内容:

点击搜索和关闭浏览器不需要加参数了。
校验标题:

搜索测试里面的内容我们也顺势一起修改一下,加个url的参数。

因为修改了搜索测试的arguments,所以必须把case的也进行修改。所以大家以后注意要提前设计好关键字的arguments,否则后面修改的时候很容易遗漏。
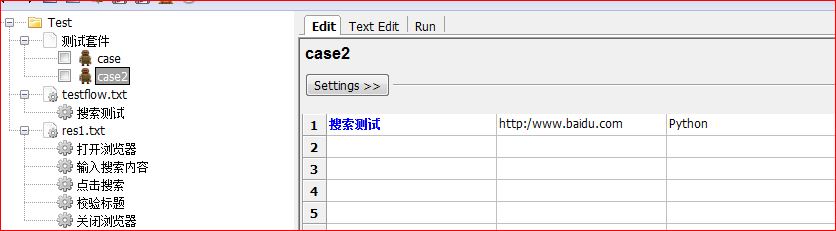
至此,我们这个案例就已经完成分层了,因为案例比较简单,所以只分了3层,分别是案例层,流程层,元素层。他们的调用关系也是逐层深入的。

一般情况下,做一个系统或项目,大概分4层就够了,如果系统比较复杂可以考虑分5层。
看一下分4层的图(手头没有例子,先借用一下吴博PPT里的图):

分别是案例层、流程层、流程构件(页面层)、元素层,加载资源也是从上到下的。
案例层中放的是流程层的关键字,流程层放的是页面层的关键字,页面层放的是元素层的关键字。
我们自己的项目分5层的:
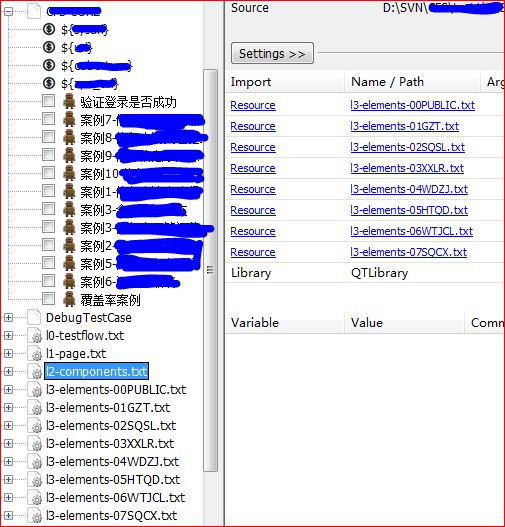
和4层的比起来,我这里多了一个components组件层。因为我们的有很多页面内容比较多,我把每个页面分成了几个区域,一个区域就是一个components。
所以我这边的加载顺序是case层加载l0-testflow,testflow加载l1-page,page加载l2-components,components加载l3-elements层。一个elements文件就是一个页面内所有的元素,由于元素较多,所以这样来组织,然后在组件层加载所有页面的元素,然后拼出相应的组件。
=============总结一下=============
这样做的好处不单是为了以后维护方便,也使得案例的架构层级清晰。越是靠近上层的部分,脚本越贴近自然语言,或者说很像我们的测试案例;越靠近下层的部分,越是接近页面元素的代码级部分。这样以后如果发生维护的时候,根据需要维护的内容,只需要在很少的地方进行调整即可。比如一个元素的id变了,那我只要在elements里面更新就行了。比如测试的流程调整了,以前是ABC的页面顺序,现在是ACB的页面顺序,那么只要在testflow层进行调整即可。
那么回到我们的标题,流程与数据分离,实际上目前我们的流程都集中在testflow以及下面的部分,而数据一般都是在案例层去给流程层传递,这就是我们的流程与数据分离了。当然,我们还可以再进一步的分离,把数据放到外面,脱离我们的案例,在运行的时候才传递进行,也是可以实现的。后面我会做个简单的例子给大家看。
=============预告一下=============
后续内容就会比较零散了,大体上我会按照关键字、变量、测试库、技巧这样几个部分进行介绍。有对某部分内容特别关注的朋友可以@我,我会及时调整,感谢各位支持。
最近有些散漫了,明早争取再补一篇~
分享到:




相关推荐
引言:什么是RFS——RobotFramework+selenium2library,本系列主要介绍web自动化验收测试方面。 引言:什么是RFS——RobotFramework+selenium2library,本系列主要介绍web自动化验收测试方面。 ==RobotFramework...
引言:什么是RFS——RobotFramework+selenium2library,本系列主要介绍web自动化验收测试方面。好久没写东西了,最近没怎么弄QTP了,之前一直想找一个能方便管理QTP对象的东东,FrameworkManage用excel管理虽然是...
引言:什么是RFS——RobotFramework+Selenium2library,本系列主要介绍web自动化验收测试方面。这一讲主要说一下工作区的Run页面,这里可以手动运行我们的案例有关的一些设置。 引言:什么是RFS——RobotFramework+...
引言:什么是RFS——RobotFramework+Selenium2library,本系列主要介绍web自动化验收测试方面。之前一直使用Selenium2Library的0.5.2版本,现在官方推出了1.0.0版本,本人在升级过程中遇到了很多的问题,于是痛下...
介绍用RFS自动化工具,将业务流程与测试数据分离
RFS自动化验收测试工具是一款测试应用软件,主要为大家的编程软件相关进行测试操作,不需要大家写代码,对测试工程师感兴趣的朋友可不要错过哟,完全免费下载。 作者留言 我第一次安装RFS用了小半天的时间 还是在...
最近刚刚接触到RobotFramework,发现这个工具倒是可以满足我的要求,而且可以结合seleniumLibrary,用来做web的自动化测试相当不错。之前我也接触过selenium,不过感觉那个工具更贴近开发人员使用,有了robot...
RFS自动化测试培训.pptx
非常齐全的RFS——RobotFramework+Selenium2library安装包
RFS+AutoItLibrary测试web对话框demo 详见我的博客:http://blog.csdn.net/tulituqi/article/details/21871247
RFS安装
基于robot framework+selenium(rfs)写的ppt文档,是工作中进行实际使用的文档,自己编写
robot FrameWork Selenium2一键安装包